别着急,坐和放宽
因为最近在重写个人站点,尝试了 NextJS 全新的 RSC 架构之后,也踩了很多坑。打算用此文记录一些实践。
在 SSR 架构中,如果请求数据在服务端,在转到 CSR 渲染时依赖 SSR 的数据时,必须要保证在 CSR 时拿到的数据和服务端一致,只有这样还能保证两端渲染一致,水合成功,否则就会出现 Hydration failed because the initial UI does not match what was rendered on the server.的错误,虽然说这个错误不会导致页面崩溃,使用下来也不会有明显的 LCP 降低,但是在开发过程中就很糟心了,会出现大量的 NextJS 红色弹窗,以及生产环境中的 Sentry 轰炸(如果接入了 Sentry)。下图是现在 kami 的糟心体验。因为实在是改不动了,所以才有了重写的想法。
Sentry 上报接口 429 限流了
在 RSC 架构中,也是以 SSR 为基础的,只是现在路由完全由 Server 接管,所以在原本 NextJS 中的 router 完全被取代了。路由渲染的开始从顶层组件开始向下都由 Server 渲染之后返回 Client,理论上如果没有碰到 use client 的组件,浏览器这边都不需要进行渲染。在大部分项目中,业务不可能这么简单,例如我的数据会随着服务端事件的推送而改变。
有一点需要注意的,必须要保证浏览器水合时数据一致,如果做不到,只能放弃该组件的 SSR 渲染。最常规的方法,但是他不能做更多的事。
CodeBlock Loading...
以上是我最开始尝试的数据传递方式,用这个方式,完全没有问题,只要保证传递的 data 都是可被 JSON 序列化的即可。
但是用了上面的方式,通过 props 传递的数据是不可变的,页面的组件由此数据驱动,需要根据后续各种事件去改变这个数据,就需要引入状态管理。
回到已经烂透的 kami,它是怎么做的。页面需要的数据请求完之后,在服务端根据获取的数据渲染完了页面返回 HTML 到了浏览器,浏览器在开始渲染的第一帧是页面的完整态,但是此时页面还不是 interactive 状态,直到 JS 加载后 React 开始介入进行 hydrate 但是由于页面的数据不是根据 props 传递的,而是都是从 store 提取,此时 store 没有完成水合导致 hydrate 后的第一帧进入了没有数据的页面的加载态,导致 React 报错 Hydration Error,从而转向 Client Render。
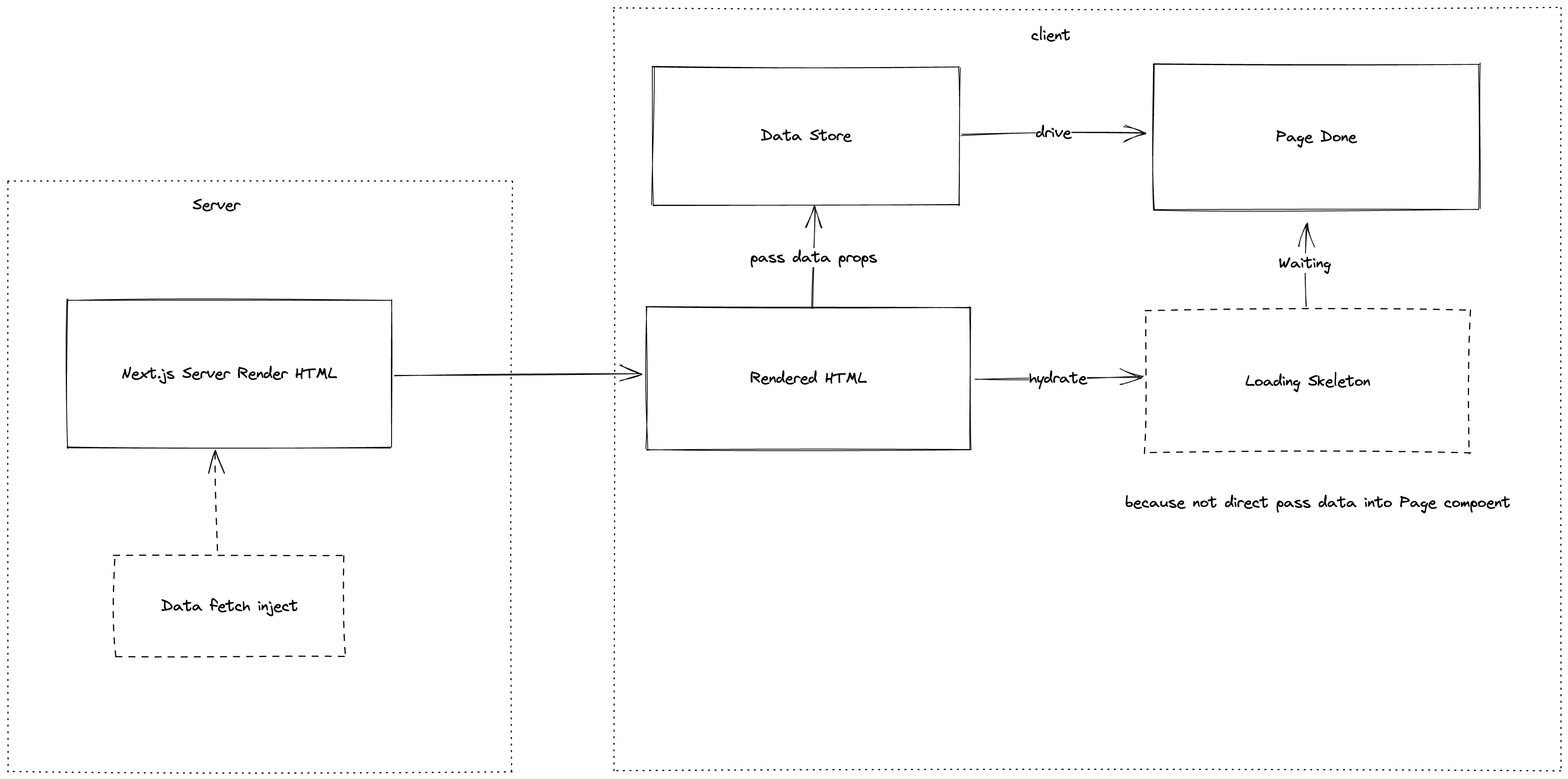
之前使用的 Zustand 看似并没有提供很好的解决方案。这次我打算用 Jotai 完成这部分的迁移。我们的页面数据依然由 Store 驱动,而不是用 props 透传。
React Query 方案
我尝试了 React Query 作为媒介,React Query 天然的提供了 Hydrate 组件,一定程度上可以解决这个问题,但是如果使用了 React Query 作为数据管理,将无法对每个组件的粒度化进行控制。React Query 的 select 能力不太灵活,而且在一些尝试中发现及时使用了 select 也无法精确粒度化到每个组件的更新。
真的简单吗?
如果使用 React Query 方案,简单的场景只需要下面这样操作就行了。
建立 ReactQueryProvider 和 Hydrate 组件,这是两个 client component。
CodeBlock Loading...
CodeBlock Loading...
然后在 layout.tsx 引入。
CodeBlock Loading...
这里注意的是,你必须在 Server 端也建立一个 QueryClient,在 Server Component 专用这个 QueryClient 而是 Client Component 不是同一个,而在 Hydrate 时使用 Server Side 的。所以在 layout.tsx 我们又建立了一个 QueryClient 供 Server Side Only 使用。我们在 RootLayout 定义了一个 Query fetch,模拟了一个随机数据的获取,并且等待这个异步请求完成再进入 Dehydrate 阶段。请注意上面设定的 cacheTime 后面会讲到。接下来验证 Hydrate 是否生效。如果没有出现 Hydrate Error 这表明没有问题。
建立 page.tsx,并转成 Client Component。
CodeBlock Loading...
这里我们禁用了 Query 的自动 refetch 的特征,保证不要刷新数据,在这个例子中,只要页面不是显示 0 就是 OK 的。
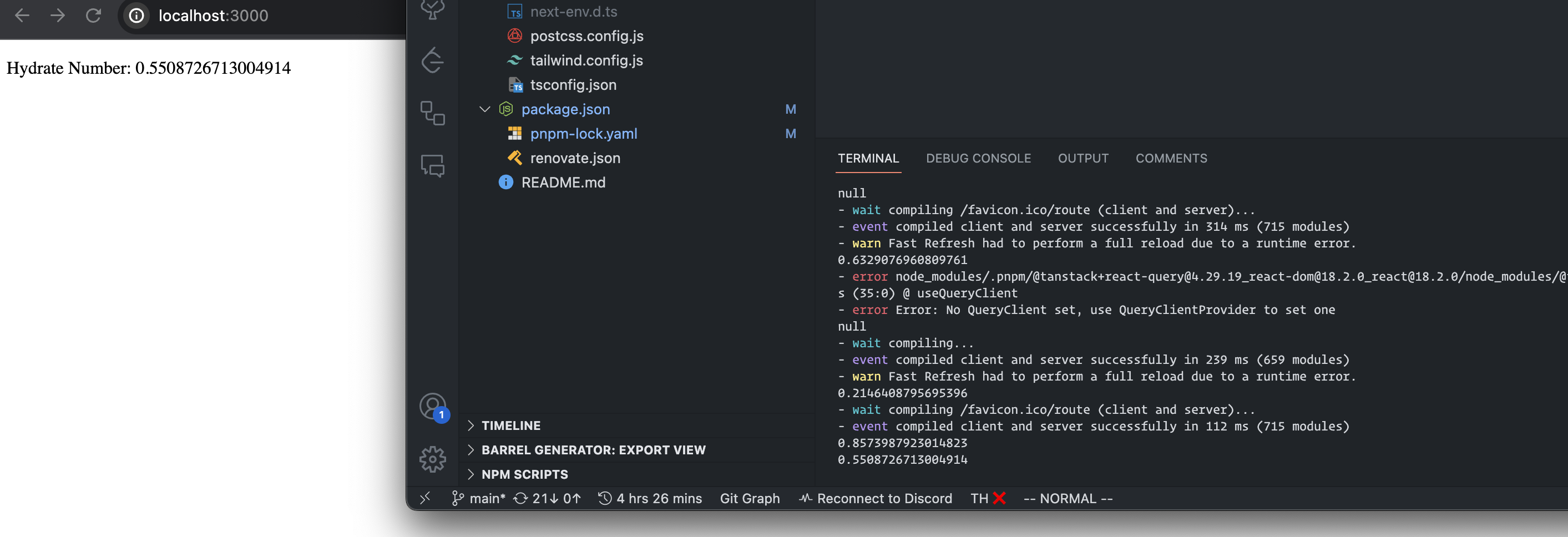
我们看到随机数和 Server 打印的一样,并且没有浏览器没有任何 Hydrate 的报错。
数据缓存
前面提到了我们在 ServerSide Only 的 QueryClient 设定了 cacheTime,这个参数可不是你认为的数据缓存时间,而是 Query 实例的存在时间,在 React Query 中所有的 Query 都在 QueryCache 中托管,只要过了这个时间 Query 就会被销毁,在 React Hook 中的 useQuery 中 Query 长期挂在组件中不需要感知这个数值,而在 QueryClient 手动 fetch 的数据也会产生 Query 实例,所以在 ServerSide 要先让一个数据多次命中同一个 Query 切记不要设置太短的时间,默认值是 5 分钟。
我们举个例子,我设定 ServerSide 的 QueryClient cacheTime 为 10 毫秒,在 queryClient fetch data 时有异步任务插入,导致没有进行到 dehydrate 时 Query 实例被销毁的情况。
CodeBlock Loading...
此时再看浏览器页面。已经没有数据。
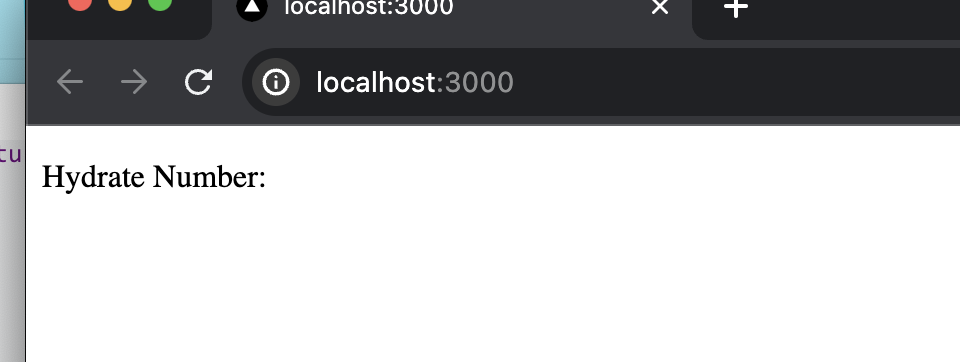
可想,要使用 React Query 并且又不想 Server 把 API 的缓存于自身还是有一点困难的。
潜在的数据泄露
如果你不是 Serverless Mode 运行这个 Next.js,由于 QueryClient 在服务端只有一个,但是访问你的站点有很多用户,他们访问着不同的站点,QueryClient 就会缓存不同的请求数据。
在 A 用户访问站点时可能包含着 B 用户访问内容的水合数据。
举个例子,编写一个 Demo。我们把 ServerSide 的 cacheTime 注释,回到默认的 5 分钟。
建立 A 和 B 页面。
CodeBlock Loading...
B 同理,把上面的 A 全改成 B。
访问 /A 和 /B。刷新页面,查看 /A HTML 源码。
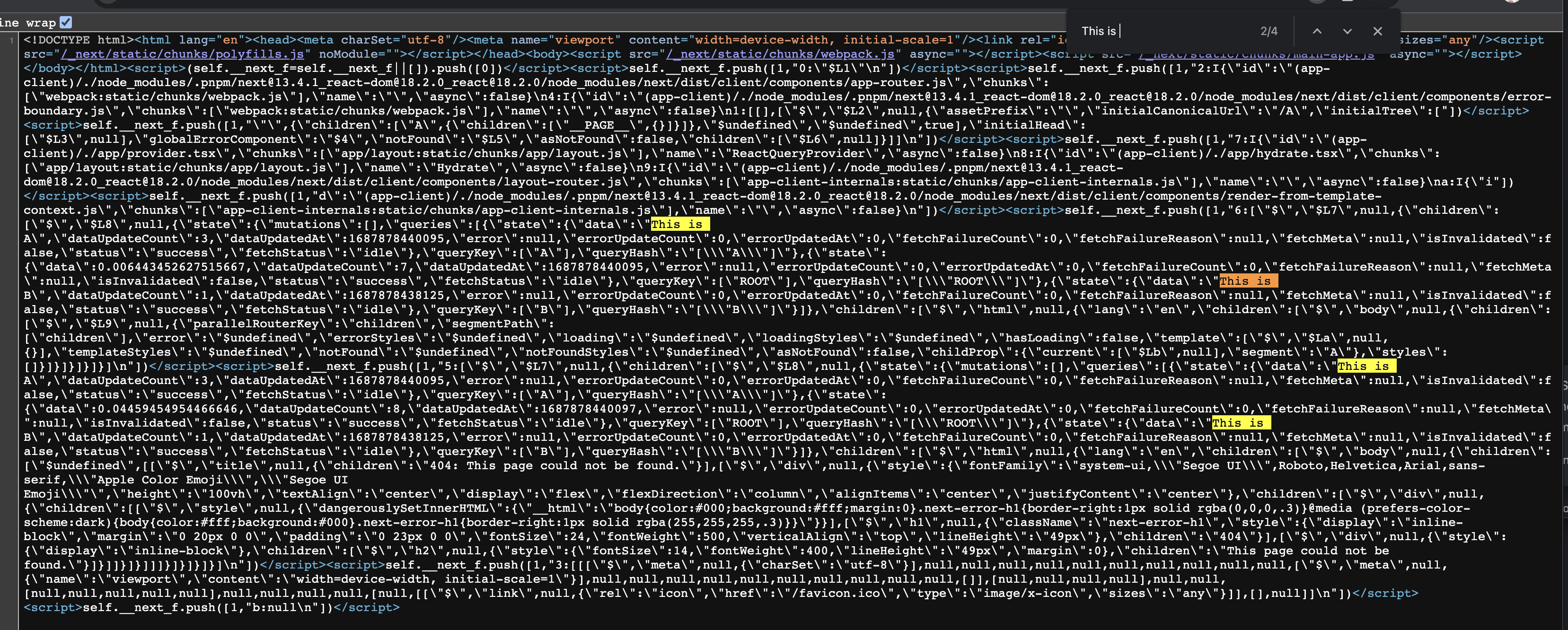
我们可以看到访问 /A 携带了 /B 的数据。
当访问量上去之后,这个水合数据会变得非常庞大,这是我们不希望看到的。而且如果你把 Cookie 转发到了服务端之后,可能会让访客看到一些不该看的东西。
如何规避,我的方案是根据 meta 去判断。可以在 query 的定义中,自定义一个 meta 键值表示这个 query 的需不要 hydrate。然后按照当前的路由只 hydrate 当前路由的数据。对敏感内容(可鉴权也和部分查看的)强制跳过 hydrate。
CodeBlock Loading...
只需要修改 dehydrateState 即可。我这边使用了 shouldHydration hydrationRoutePath skipHydration forceHydration 控制 hydrate 状态。
参考使用方法:
CodeBlock Loading...
看到这里,你可能会说,需要这么麻烦么,在 RootLayout 组件内部重新创立一个新的 QueryClient 实例,不就能保证每个请求的数据不会被污染么。确实 React Query 文档中提到的方案的也是如此,但是这仅仅是在传统 SSR 架构中适用,他也存在很多局限性,例如没有使用这种方式,QueryClient 将不能被其他 Layout 调用,例如在子 Layout 中的 Data fetching 必须建立新的 QueryClient,然后再次使用 Hydrate 组件包裹会存在大量额外的开销。
在 React 18.3 中提供的 cache(Next.js 已实现该方法)方法或许可以解决这一方案,使用 cache(() => new QueryClient()) 包裹使得在此 React DOM 渲染中始终命中同一个 QueryClient。这样的方案虽然解决了跨请求状态污染,但是在高并发中无法享受到单实例带来的请求 Dedupe 红利,瞬间发出太多请求带来的超负载也需要考虑。
这里就不再过多赘述了。
总之在 React Query 还是需要考虑过多的问题,从而复杂度上升,促使我转向其他方案。
Jotai
写累了。且听下回分解。